創造するAI ~アートを拡張する人工知能の可能性

この記事をシェアする

クリエイティブ分野への人工知能(AI)の活用が目覚ましい勢いで進行している。
2019年11月、AI研究の非営利団体OpenAIは、人が読んでもほぼ違和感を覚えない文章をAIにより生成する言語モデル「GPT-2」のフルモデルを公開した。最初に人間が入力した文章に続けて、論理的に破綻のない文章を作成し続けることができるもので、フェイクニュース等への悪用への危惧から、同年2月に一部が初公開され、段階的に全公開へ至ったという経緯を持つ。
また、同じく同年11月、仏芸術家グループObviousによるAI生成絵画2点が、オークション企業Sotheby’s(サザビーズ)を通して販売されることが発表された。ObviousによるAI生成絵画については、前年2018年の10月に『エドモンド・ベラミーの肖像』が43万2,000ドル(約4,800万円)で落札され、世界的ニュースとなったことが記憶に新しい。
さらに、翌12月には、Amazon Web Services(AWS)が簡単なメロディを入力するだけでAIが複数の楽器を組み合わせた音楽を生成する電子キーボード「AWS DeepComposer」を発表している。
本稿では、絵画、映像、音楽、小説等クリエイティブ分野へのAIの活用について、その現況を概観し、内包する課題も合わせ、今後について展望する。
背景となる技術:GANの台頭
AIが創作活動に与するようになった背景には、2つの技術の急速な進展がある。
ひとつが、自然言語処理技術の高度化であり、もうひとつが敵対的生成ネットワーク(Generative Adversarial Network:GAN)の誕生と発展である。
前者は言語系の生成作業において、後者は画像および音楽系の生成作業において有用な背景技術であり、特にGANは、それまで画像認識を活躍の主戦場としていたAI(認識系AI)の活躍の場を拡大、生成系を主戦場とするAI(以下、「生成系AI」という)を誕生させたという点で、重要で、注目度の高い技術だ。
GANのアーキテクチャは、生成ネットワーク(Generator Network)と識別ネットワーク(Discriminator Network)という2つのネットワークから成る。概念的には2つのネットワークを競わせながら、学習をさせていく「教師なし学習」で、Generatorが生成する偽物についてDiscriminatorが真偽を判定するプロセスを何度も繰り返すことで、Generatorが本物に近い偽物を生成できるようになるというものだ。
GANは2014年、GoogleのAI研究の第一人者イアン・グッドフェロー(Ian Goodfellow)氏らにより発表された「敵対的生成ネットワーク」と題された論文によって提案されたが、その後、DCGAN、StackGAN、StyleGAN、CycleGAN、pix2pix、Age-cGAN、BigGAN等、いくつかの応用研究によるアーキテクチャを生み出し、現在に至っている(表1)。各アーキテクチャの提案には、各々が生成する有用な適用例も提示されている。例えば、CycleGANでは、画像同士の特徴の相互変換を行う。馬とシマウマの画像の相互変換(図1)、写真と絵画の相互変換、異なる季節に撮影した写真の相互変換、画家の画風に沿った画像の変換などが可能だ。最新のアーキテクチャであるBigGANでは、驚異的なまでの高い品質の画像を生成できるレベルに達しており(図2)、これらの成果もあって、活用事例も増加の一途をたどり、実用面での企業の開発競争が激化している。
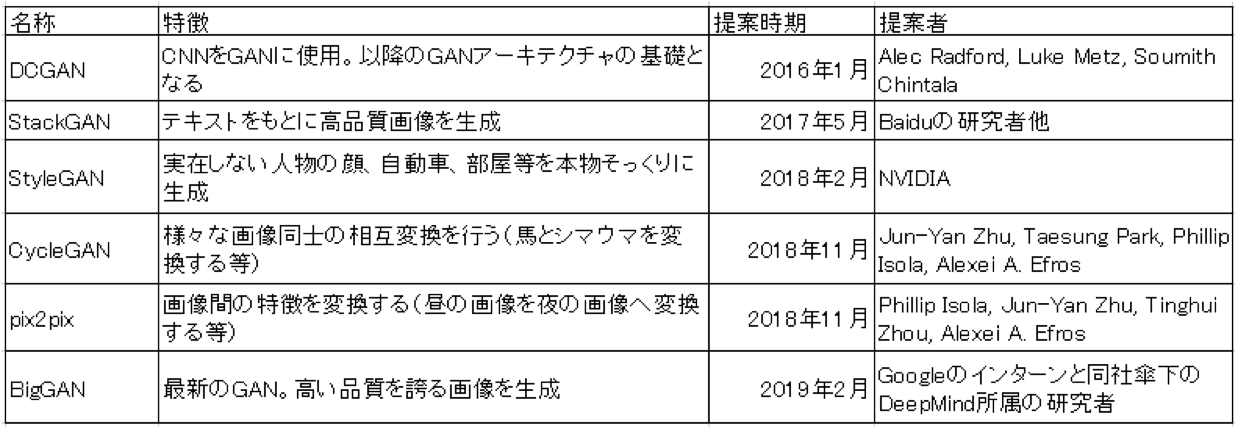
【表1】GANアーキテクチャの例
(出典:各種公表資料より筆者作成)

【図1】CycleGANによる馬とシマウマの変換
(出典:Zhu, ,Park, Isola, and Efros (2018)1)

【図2】BigGANによる生成画像
(出典:Brock, Donahue, and Sumonyan(2019) 2)
クリエイティブ分野へのAIの活用例
GANの台頭もあり、現在、クリエイティブ分野において、様々なかたちで生成系AIが活用されており、特に画像分野において大きな成果をあげている(表2)。
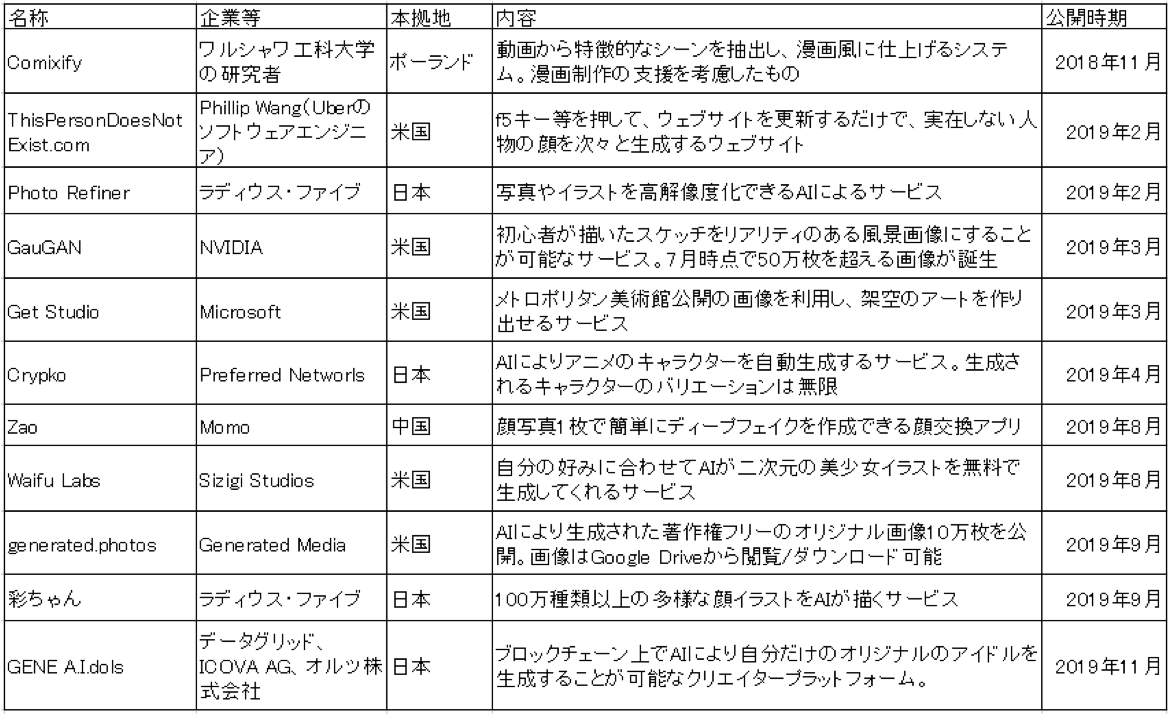
【表2】生成系AI実用化の例
(出典:各種公表資料より筆者作成)
例えば、UberのソフトウェアエンジニアPhillip Wang氏により作成され、2019年2月に公開された、「ThisPersonDoesNotExist.com」はそのわかりやすい例だ。このウェブサイトを訪れた閲覧者は、サイトを更新する度に、リアルタイムで生成される実在しない人物の顔を次々と見ることになる。
さらに、AIにより生成された著作権フリーのオリジナル顔画像10万枚をウェブサイトにて閲覧およびダウンロード可能な「generated.photos」(米Generated Media による)、簡単なスケッチを数秒でリアリティのある風景画像へ変換する「GauGAN」(米NVIDIAによる、図3)など、有用で斬新なサービスを挙げれば枚挙に暇がない。

【図3】GauGAN
(出典:NVIDIA 3)
生成系AIの活用はアニメーションの分野でも進んでいる。
動画から特徴的なシーンを抽出し、漫画風に仕上げる「Comixfly」、アニメのキャラクターを自動生成する「Crypko」、100万種類以上の多様な顔イラストを描く「彩ちゃん」等のウェブ上のサービスが公開されている。
いずれも、映画や動画、ゲームの制作において、活用が可能なものであり、その広がりによる省力化、コスト削減も期待される。
また、音楽分野での活用も進んでいる。
ルクセンブルクのスタートアップAIVA社が開発したクラッシック音楽専門のAI作曲家AIVAは、フランスの著作権団体SACEMにより作曲家として認められた世界最初のバーチャルアーティストだが、プロジェクト「From the Future World」にて、ドヴォルザークの新曲を作曲、楽曲は2019年11月15日にプラハにおけるコンサートにて演奏されている。
小説の分野では、2016年3月にAI創作小説が、「星新一賞」の1次審査を通過したニュースが世間の耳目を集めた。しかし、ここでのAIは、人間が作成したプロットに従い、小説文章を記述しただけであるとのこと。電子出版ベンチャーのBooks&Companyがカンボジアのキリロム工科大学と提携して進めるAIによる小説執筆プロジェクトのように、一定の成果もあがっているが、AIによる完成度の高いプロットの作成には技術的に高い壁がある。現時点での小説創作へのAIの活用は、AIにより生成された画期的なアイデアを人間のプロット作成に役立てていくというレベルにとどまっているようだ。
主要各社の動向
以下では、主要各社の動向について記述する。
前述のとおり、生成系AI活躍の端緒をつくったのは、Google在籍のAI研究者である。Googleは現在でも、この分野の研究における先頭集団にいて、画期的な研究結果を公表、実用化を進めている。最近の成果としては、多様性に難があるといわれるGANの弱点を補う画像生成技術VQ-VAE-2の提案、2次元画像から、空間情報を推測して、3次元画像を生成できる技術GQN(Generative Query Network)の開発、文章生成支援機能SmartComposeのGmailおよびGoogleドキュメントへの提供などがある。
Microsoft
Microsoftも活発な事業活動を続けている。同社は2018年1月、テキストからあらゆる画像を生成する技術「ドローイングボット」の研究過程を公表しており、一面では同社が進める対話型AI開発への寄与が想定されるが、活用範囲は幅広く、画家やインテリアデザイナーのスケッチの補助、音声による写真編集ツール、台本に基づいたアニメーションの自動生成への応用も期待される。同社の直近の動向としては、米ニューヨークのメトロポリタン美術館公開の画像データをもとにAIにより架空のアートを作り出せる「Gen Studio」の開発とウェブサイト上での公開、Wordでの文章の作成をAIで支援するクラウドベースの新機能「Ideas」の公開などがある。また、同社は冒頭で紹介したOpenAIへも10億ドルを出資し、複数年にわたるパートナーシップを締結している。OpenAIは、イーロン・マスク氏により2016年に設立されたが、汎用人工知能(Artificial General Intelligence:AGI)の研究を進めており、Microsoftの視界の先に、AGIがあることは間違いない。
NVIDIA
画像関係の生成系AIにおいて、際立つ成果をあげているのが、半導体メーカーの米NVIDIAである。同社はPCやゲームコンソール等でインタラクティブなグラフィックスを作り出すGPUの開発に定評があり、画像生成系AIの研究は同社の事業内容を考えれば、必然的なものといえよう。同社が開発し、2018年2月に公表した革新的技術のひとつが「StyleGAN」だ。実在しない人物の顔等、本物そっくりのフェイク画像を生成可能な技術で、顔だけではなく、自動車、部屋等の生成も可能なものだ。また、直近の動向としては、2019年3月発表の、スケッチを数秒でリアリティのある風景画像へ変換できる前述の「GauGAN」や、同年11月発表の、動物の表情とポーズを別の動物に反映できる「GANimal」など、同社は、特に映画やゲームの制作において省力化と品質アップへの貢献が期待できるAI技術を発表している。
その他の企業
この他、米Apple、Facebook、Amazon、中国Baidu(百度)、韓国Samsung等も生成系AIの研究と実用化の競争に参戦し、しのぎを削っている。
Appleは、2019年3月、前述のGANの産みの親であるイアン・グッドフェロー氏をGoogleから引き抜き、同社で雇用している。Facebookは2019年4月、現実の人間を簡単にゲーム内のキャラクターへ変換する技術「Vid2Game」を発表している。Amazon傘下AWSの音楽生成キーボード「AWS DeepComposer」については冒頭に紹介したとおりだ。Baiduは、2017年5月に発表された、GANの革新的技術のひとつ「StackGAN」誕生において主要な役割を果たしている。これは、対象を説明するテキストだけをもとに高品質画像を作成するものだ。Samsungは2019年5月、対象となる人の顔の静止画像から対象者が「話をしている」動画を生成するシステムを開発している。対象となる顔のモデルの作成に必要なのは1枚の写真のみという。
今後の課題
AIが限りなく本物に近い偽物を生成することができるとすれば、問題となるのは、偽物を本物として悪用された場合の真贋の判定である。
この問題を正面から突き付けたのが、ディープフェイクである。
ディープフェイクとは、偽動画のことで、2017年11月にソーシャルブックマークサイト「Reddit」へ投稿された動画「deepfakes」がその発端と言われる。現在、生成系AI技術の進展により、真偽の判断が簡単にはつかない動画の作成が可能となっており、虚偽情報の拡散による社会的問題の発生を危惧する声があがっている。
過去にはトランプ米大統領を罵倒するオバマ前大統領の偽動画、データの支配について語るFacebook CEOマーク・ザッカーバーグ氏の偽動画などが投稿され、いずれも広く拡散し、話題となっている。
YouTubeにはディープフェイクを専門に扱うチャンネルも存在し、また、中国では顔写真1枚で簡単にディープフェイクを作成できる顔交換アプリ「Zao」がiOS App Storeの無料アプリ人気ランキング1位を獲得しているなど、ユーザー利用の裾野の広がりも考慮すると、早急な真偽判定技術の開発が必要だろう。現在米国では、Facebook、Microsoft等のIT各社と大学研究機関が合同で取り組むディープフェイクを見破るAI開発プロジェクト「ディープフェイク検知チャレンジ(Deepfake Detection Challenge:DFDC)」が実施されるなど、真偽判定技術開発への取り組みが進んでいる。
また、著作権の問題もある。
現行の法律は、人間による創作を想定したものであり、生成系AIによる創作は想定されていない。AIが単独で行った創作の場合など、今後、AIが関わった様々なタイプの創作物の権利帰属について、疑義が生じる余地があることは想像に難くない。創造性の抑圧を生まないかたちでの柔軟な対応が期待される。
まとめ:創作活動におけるAIとの共生
「AIが人間の仕事を奪う」という言辞がバズワードとなり、まことしやかに囁かれたのは、つい先日のことのようだが、その言葉を証明するかのようにAIはあらゆる分野に進出しており、クリエイティブ分野での広範な浸透も掌中にしつつある。果たして、AIはクリエイティブ分野で人間の仕事を奪うだろうか。
近い将来においては、答えは否である。現在のAIの場合、創作物の生成には、人間の手による動機づけ(例えば、音楽生成における導入部のインプット、学習データの提供)が必要である。人間の感性へ訴える創作物をAIが単独で生成するためには、少なくとも、自ら動機づけを行える汎用人工知能(AGI)の登場を待たねばならないだろう。
一方で、現在の生成系AIは、クリエイティブ分野における創造の新しいかたちを示唆してくれている。人間とAIの共創による創作物の制作である。
AIが生成するものには、人間の視点で見ると、奇抜な点が散見される。その奇抜さを上手に利用すれば、マンネリに陥った創作活動に新風を吹き込むことも可能だろう。
既に実例もある。例えば、2019年3月、ファッションデザイナーのエマ理永氏は、理化学研究所とコラボレーションし、AIの着想を生かして作ったドレスを披露するファッションショーを開催している。
そうした意味でも、今後、常識の壁を軽々と打ち破るAIの着想が前向きに活用され、人間の創造力拡張の源泉となり、創造的で斬新な作品が次々と産み出されていくことが期待される。
- Zhu, J-Y.,Park, T., Isola, P., and Efros, A. A. (2018) “Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks”
- Brock, A.,Donahue, J., and Simonyan, K. (2019) “Large Scale GAN Training for High Fidelity Natural Image Synthesis”
- https://blogs.nvidia.co.jp/2019/12/09/nvidias-gaugan-wins-a-2019-popular-science-best-of-whats-new-
award/
※この記事は会員サービス「InfoCom T&S」より一部無料で公開しているものです。
調査研究、委託調査等に関するご相談やICRのサービスに関するご質問などお気軽にお問い合わせください。
ICTに関わる調査研究のご依頼はこちらこの記事をシェアする
関連キーワード
原田 昌亮の記事



関連記事




InfoCom T&S World Trend Report 年月別レポート一覧

ランキング
- 最新
- 週間
- 月間
- 総合
各種サービスへの問い合わせ



情報通信サービスの専門誌の無料サンプル、お見積り

グローバルICT市場の総合データ集の紹介資料ダウンロード