Accidents will happen ~クラウドの事故について考える

この記事をシェアする

デジタル化の進展や、クラウドの活用が進んでいる、というのはもはや常套句となり、クラウドはむしろ、社会的機能の一部としてなくてはならないインフラストラクチャーとなっている。そうした状況の中で、ひとたびこれらのサービスで障害が発生すると重大な影響が生じることになる。これは、原因が悪意ある攻撃であれ、故障などの事故であれ同じことである。IPAの「情報セキュリティ10大脅威」においても、「予期せぬIT基盤の障害に伴う業務停止」は「2020」において6位にランクインし(前年版では16位)、「2021」においても7位となるなど、さまざまな悪意ある攻撃と並んで、障害によるサービス停止などの影響が大きな問題となってきていることがわかる。
クラウドサービスにおいては、サービス提供者によって設備が冗長化されており、ユーザーから見れば、システム構成を気にすることなく、いつでも望むサービスを望む時に、望む量だけ利用することができるのも大きなメリットの一つである。もし軽微な障害があったとしても、ユーザーは障害があったことにすら気付かないことも珍しくないだろう。しかし、重大な故障が発生すると、突然長時間の利用中断やデータの損失などの事態に直面することとなり、それらは無視できない社会的影響を与えることにもなる。そこで、本稿では、最近のクラウドに関する事故事例を取り上げて実態を分析し、事業者やユーザーの取り得る対策について検討したい。
なお、本稿は、ここで取り上げる事故のみが殊更に重大であると主張するものでも、当該事業者・関係者等を批判するものでもなく、あくまでクラウドサービスにおけるリスクとその対策の分析を目的とするものであり、また分析においてはすべて公開情報をもとにしていることをあらかじめお断りしておく。
最近の事故を振り返る
Google Cloudにおける障害
「情報セキュリティ10大脅威2021」において、2020年12月に発生したGoogle Cloudの障害が取り上げられている。この障害は、Googleの報告[1]によれば、2020年12月14日の47分間、Google OAuthアクセスを必要とする顧客向けのGoogleサービスが利用できない状況が発生したものである。これにより、「YouTube」「Gmail」「Google Cloud Platform(GCP)」などにアクセス障害が生じたと報じられている[2]。これは、同社の発表によれば、認証システムにストレージを自動で割り当てるクォータシステムにおいて、システムの変更時のミスに伴って、認証システムの容量が0となってしまったことによるものとされている。クォータシステムが保持する猶予期間の間は問題にならなかったが、期間が終了した結果、自動クォータシステムがユーザーIDサービスの許容クォータを減少させ、この事故が発生した。原因となった事象は47分とされているが、これを利用する各サービスではトラフィックの急増等により、もとの問題が解決した後でもエラー等の影響が残った。個人、法人ともに多くのユーザーを持つサービスが影響を受けたことから、社会的なインパクトも大きかった。
Slackにおける障害
2021年1月4日の朝6時頃から8時30分頃(太平洋標準時)の間にはSlackで大規模なアクセス障害が発生した[3]。この障害では、まず、Slackでエラーレートの上昇が見られた。初期段階で、ネットワークが広範囲に劣化している兆候が見られたため、同社は主要なクラウドプロバイダーであるAWSにエスカレーションを行った。しかしその後、ネットワークの障害が自動スケーリングに影響を及ぼした。ネットワークの問題が原因で待機時間が長くなって一時的にCPU使用率が下がったことから自動的にダウンスケールが始まった一方で、その後にApacheのワーカスレッドの使用率が上昇し、大規模な自動アップスケーリングが行われたのである。そして、ネットワーク障害の影響で接続時間や応答時間が長くなり、しかも通常よりも多くのシステムリソースを使用していたことから、プロビジョンサービスがリソースのボトルネックに到達し、新たなリソースのプロビジョンが行えなくなった。また、これによりモニタリング用のダッシュボードに必要なインスタンスもプロビジョンできなくなっていた。このような障害が重なり、Slackは一時的に利用不可能な状態になった。
結局、この障害の原因は、SlackがAWSで利用している専用の仮想プライベートクラウド(VPC)間を接続するAWS Transit Gateway(TGW)にあった。年末年始でトラフィックが下がっていたところに年始のトラフィックが大量発生したにもかかわらず、TGWがそれに合わせてスケールすることができなかったのである。そのことをAWSのエンジニアが発見し手動で修復したことで、事態は解決に向かった(図1)。
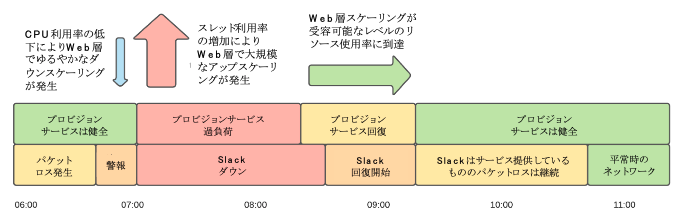
【図1】障害と回復のタイムライン
(出典:Slack’s Outage on January 4th 2021 (Slack)
https://slack.engineering/slacks-outage-on-january-4th-2021/(訳は筆者による))
CDNにおける障害
2021年6月と7月には、続けてCDN(Content Delivery Network)での障害が発生した。CDNはDNSやキャッシュ等を活用することで、コンテンツ配信の最適化やWebサイトの応答速度向上に用いられることから、多くのユーザーやトラフィックを持つ人気サイトで利用されることが多い。6月に発生したFastlyのサービス障害[4]でも、Spotify、PayPal、VimeoやCNN、The New York Times、BBCなど世界中の多くのサイトが影響を受けた[5]。日本でもメルカリ、日本経済新聞(電子版)などが影響を受けた可能性があると報じられている[6]。同社が5月に実装を開始したソフトウェアにバグが含まれ、ある設定変更をトリガにそのバグが顕在化し、障害につながったとみられている。
同7月にはAkamai Technologiesのサービスでも障害が発生した。ソフトウェア構成のアップデートによりDNSシステムにバグが発生したことが原因で、同社の発表[7]によれば障害は最大1時間続いた。ソフトウェア構成のアップデートをロールバックすると、サービスは通常通り動作するようになった。この障害でも、Amazon.com、American Airlines、HSBCが影響を受けている[8]ほか、日本でも五輪公式サイト、JAL、PlayStation Networkなどでアクセス障害が一時的に発生したと報じられている[9]。なお、同社はこれがプラットフォームに対するサイバー攻撃ではないことを確認したと発表した。
AWS東京リージョンにおける障害
2021年9月2日にはAWSの東京リージョンで障害が発生した。この障害では三菱UFJ銀行やみずほ銀行のアプリ、ネット証券各社のサイト、KDDIの「au PAY」に影響があったほか、ANAでは羽田空港でのチェックインサービスで障害が発生し、一時的に搭乗手続きができなくなった。JALでも貨物に関するシステムに影響があった[10]。AWSの報告[11]によれば、これは、AWSのユーザーが東京リージョンに接続するDirect Connectのパケットロスの増加が検知されたことに始まった。同社が影響を受けているデバイスをサービスから除外する等の対応中にも他のネットワークデバイスでも同じ障害が発生し、Direct Connectを利用中のユーザーのネットワークに輻輳、接続の問題、またはパケットロスの増加が発生し、適切なキャパシティを維持することができなくなった。同社のエンジニアは、この障害が頻度の低いネットワークコンバージェンスイベントおよびファイバー切断に対するネットワークの反応時間を最適化するために導入された新しいプロトコルに関連している可能性があると判断し、これを無効化する修復作業を行った結果、6時間12分後にDirect Connectサービスが通常の動作に戻った。その後の原因究明作業によれば、この事象は、ネットワークデバイスのオペレーティングシステム内の問題に起因するもので、しかもこの欠陥が問題を引き起こすには、非常に特殊なパケット属性とコンテンツのセットが必要であり、継続的にこのシグニチャーに一致し得たカスタマートラフィックによってこのイベントが発生したことが明らかになった。なお、同社は悪意のある振る舞いがあったとは考えていないとしている。
事例の検討
これらの事例を見ると、いくつか特徴的な共通点が見られる。まず、Slackのケース以外では、一つの基盤となるクラウドサービスの障害が、複数の他社のサービスにも大きな影響を与えていることが挙げられる。特定のクラウドサービスに一部もしくはすべてを依存している他社サービスは、基盤サービスで重大な不具合が発生すれば共倒れになってしまう。本来、複数リージョンでの冗長化などの対策を取り得るはずではあるが、コストが増えること(クラウドの利用料金だけではなく、冗長化システム構築のコスト、運用コスト等も含めて)など、課題も大きいことが推察される。マルチクラウド、マルチCDNによる冗長化といった対策も原理的には考えられるが、そうなるとさらに開発、運用コストが増大するとともに、障害時の切り替えなども複雑になり、それが新たな事故の発生要因ともなりかねない。
もう一つは、GoogleのケースとSlackのケースで、自動的にスケールアップ/スケールダウンする仕組みが関係していることである。クラウドリソースを効率的に活用するためにも、またキャパシティ不足による障害を防ぐためにも、スケールアップ/スケールダウンの仕組みは有効だが、それを含めた複雑なシステムが予期せぬ動きをしたことが問題になっている。
あわせて、GoogleとAWSのケースでは、不具合が時間差で発生していることも注目すべき点と考えられる。工事は無事に終わっているにもかかわらず、かなり後に障害になっている。工事を行う場合、検証環境での事前検証は行っているだろうが、このような問題への対処はさらに難しいだろう。
また、全体に、さまざまな機能の導入やバージョンアップにより、システムが高度化、複雑化していることも課題だろう。機能が増え、より効率的に運用できるのは良いことだが、一方で、一つの事象が原因でも、それが複数機能の不具合につながって問題が拡大していっていることが多く、切り分けや対処も困難になっていると考えられる。各社の報告では、多くの場合、解決への道のりを中心に報告されるが、その前の段階では相当な試行錯誤が行われていると思われる(試行錯誤を含めて公開、報告する企業もある)。また、障害の間のリクエストが累積し、機能回復後に過負荷が発生する等により、もとの要因が解消した後でもユーザーにとっては障害(に見える)状態が続くことも少なくない。
まとめ
これらの障害に対応するにはどうすればよいのだろうか。もちろん守るべきものとの比較で決まるし、コストとのトレードオフとはなるものの、ユーザーとしては、単一のシステムを利用するのではなく、リージョン(ロケーション)や、場合によってはサービス提供事業者を分散させることにより、少なくとも単一事故による業務停止やデータの損失を防ぐことは引き続き重要と言えるだろう。また、運用がクラウドサービス事業者の責任に属する基盤の部分であっても、信頼性の検証や監視を行い、自身のデータとサービスを守ることはやはりユーザーに求められると考えられる。
本稿は本誌2017年10月号に掲載した拙稿「事故は起こる」と同様、事故が容易に防ぎ得ると主張するものではない(そのため、このタイトルとしている)。すべての事故を想定し事前に対処するのは不可能だが、だからといって「想定外」と逃げることは許されない。事故は起こるものとの前提で、システムの可用性、機密性、完全性の観点から一定の基準を設け、それを担保する仕組みを作ることは有効と考えられる。対策の立案には他社・他サービスのアクシデント、インシデント事例の分析が参考になるだろう。技術の進化とシステム構成の変化に伴って注意すべき点や対処すべき点は変わっていくが、この原則は変わらないと思われる。
2021年初頭に発生したSlackの事故の報告3の末尾にはこのように記載されている。「すべての障害は学習の機会であり、将来の信頼性に対する計画外の投資でもあります。私たちはこの事故から多くを学びました。そして、いつものように、この予定外の投資を最大限に活用し、2021年とそれ以降には、私たちのインフラをより良いものにしていきたいと考えています」。すべての問題を一度に解決する銀の弾丸はないが、事例から教訓を得て知識を積み上げることで、雲の向こうに希望の兆しを見つけたいものである。
[1] Google Cloud Status Dashboard https://status.cloud.google.com/incident/zall/20013
[2] Google: Here's how our huge Gmail and YouTube outage was due to an errant 'zero' https://www.zdnet.com/article/google-heres-how-our-huge-gmail-and-youtube-outage-was-due-to-an-errant-zero/
[3] Slack’s Outage on January 4th 2021 https://slack.engineering/slacks-outage-on-january-4th-2021/
[4] Summary of June 8 outage https://www.fastly.com/blog/summary-of-june-8-outage
[5] Twitch, Pinterest, Reddit and more go down in Fastly CDN outage (Update: Outage resolved after 1 hour) https://techcrunch.com/2021/06/08/numerous-popular-websites-are-facing-an-outage/
[6] 大手CDNプロバイダーFastlyで“世界的な障害” メルカリ、note、TVerなど複数サービスに影響か https://www.itmedia.co.jp/news/articles/2106/08/news156.html
[7] Akamai Technologies Twitter https://twitter.com/Akamai/status/1418257652660985858
[8] Akamai Says It Has Fixed Issues That Affected Many Websites https://www.bloomberg.com/news/articles/2021-07-22/ups-home-depot-among-websites-hit-by-widespread-service-outage
[9] 五輪やJALの公式サイト、PSNなどで一時アクセス障害 AkamaiのDNSが原因か https://www.itmedia.co.jp/news/articles/2107/23/news027.html
[10] アマゾン子会社AWSで障害 データ管理サービス 広範囲に影響 https://www3.nhk.or.jp/news/html/20210902/k10013238691000.html
[11] 東京リージョン(AP-NORTHEAST-1)で発生したAWS Direct Connectの事象についてのサマリー https://aws.amazon.com/jp/message/17908/
※この記事は会員サービス「InfoCom T&S」より一部無料で公開しているものです。
当サイト内に掲載されたすべての内容について、無断転載、複製、複写、盗用を禁じます。InfoComニューズレターを他サイト等でご紹介いただく場合は、あらかじめ編集室へご連絡ください。また、引用される場合は必ず出所の明示をお願いいたします。
調査研究、委託調査等に関するご相談やICRのサービスに関するご質問などお気軽にお問い合わせください。
ICTに関わる調査研究のご依頼はこちらこの記事をシェアする
関連キーワード
左高 大平 (Taihei Sadaka)の記事


関連記事




InfoCom T&S World Trend Report 年月別レポート一覧

ランキング
- 最新
- 週間
- 月間
- 総合
各種サービスへの問い合わせ



情報通信サービスの専門誌の無料サンプル、お見積り

グローバルICT市場の総合データ集の紹介資料ダウンロード