データ・AIの著作権法制と、ヒトDTCへの適用に関する若干の検討

この記事をシェアする

はじめに
データや人工知能(AI)は、あらゆる産業分野で競争力の源泉となっており、その効果的な利活用は国や企業の発展に大きな影響を与えるものである。データ・AIの効果的な利活用を図るためには、適切な権利保護と、利用を阻害しない制度が整っている必要があるが、著作権法制に関しては、世界に先駆けて日本で急速に議論が進められている状況であり、データ・AIの効果的な利活用を目的とした著作権法の改正が2018年になされている。
ところで、NTTが実現を目指しているIOWN(Innovative Optical and Wireless Network)構想[1]を構成する3つの主要技術分野の一つである「デジタルツインコンピューティング」(DTC:Digital Twin Computing)では、ヒトの意識や思考をデジタル表現することにも挑戦するものとされている[2]。従来のデータ・AIの著作権法の議論では、特定のヒトについて、意識や思想のレベルまで再現することは必ずしも想定されてこなかったように思われる。
本稿は、データ・AIに関する日本の著作権法制の状況や議論を概説するとともに、それらの議論をDTC、特に特定個人の内面をも再現するヒトDTCに当てはめた場合の課題について、若干の検討を行うものである。
機械学習によるAIの生成過程のイメージ
まず、本稿における機械学習によるAIの生成過程のイメージを共有する。図1は、内閣に設置された知的財産戦略本部の検証・評価・企画委員会による「新たな情報財検討委員会 報告書」に掲載された図を引用したものである。本稿では、図1のイメージに従って、データ・AIの著作権法制について概説していく。
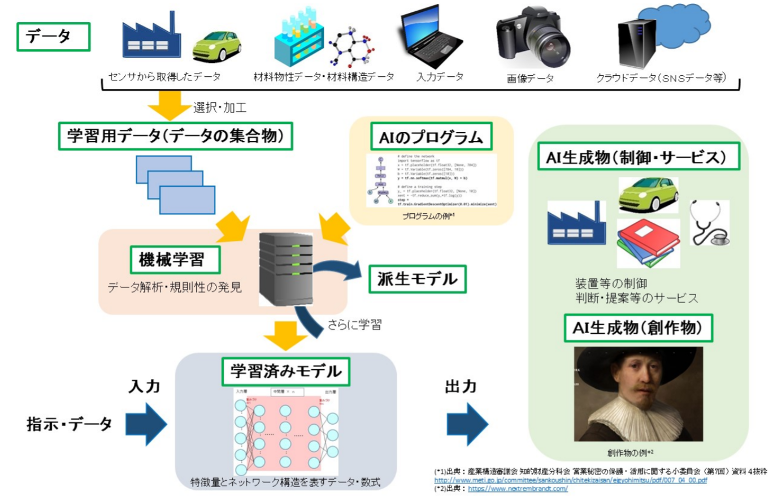
【図1】機械学習を用いたAIの生成過程のイメージ
(出典:知的財産戦略本部 検証・評価・企画委員会「新たな情報財検討委員会 報告書」24頁
【図6(機械学習を用いたAIの生成過程のイメージ)】(2017)(https://www.kantei.go.jp/jp/singi/titeki2/tyousakai/kensho_hyoka_kikaku/
2017/johozai/houkokusho.pdf))
図1を簡単に説明すると、IoT機器などから収集したデータや、SNS等から収集したデータなど、大量のデータを集めて「学習用データ」(データの集合体)を構築する。学習用データを用いて学習前の「AIプログラム」に特定の機能を持たせることを目的として学習をさせ、「学習済みモデル」を生成する。学習済みモデルに新たなデータや指示を与えることで、「AI生成物」(AI創作物)が生成される。学習用データとAIプログラムで学習済みモデルを生成する学習手法が「機械学習」であり、機械学習には大別して、教師あり学習、教師なし学習、強化学習がある。近年注目されている深層学習(ディープラーニング)は教師あり学習での活用が一般的であるが、いずれにも応用可能とされる。図1が掲載された報告書では、AIとして、深層学習を含む機械学習を用いたものに限定して検討がなされており、著作権法におけるAIの議論がなされる際も基本的に同様であるため、本稿でもAIとして機械学習を用いたものを想定するものとする。
データ・学習用データ関連の著作権法制
データの著作権保護
著作権法は、著作物を「思想又は感情を創作的に表現したものであつて、文芸、学術、美術又は音楽の範囲に属するものをいう」と定義している(著2条1項1号)。著作物として認められるためには思想・感情の創作的表現であることが必要であり、測定データといった、単なる事実を示したものにすぎないデータは、思想・感情を創作的に表現したものとは言えないことから、IoT機器から取得した事実を計測したデータ等は著作物として認められないと考えられている。
一方で、画像データ等、何らか思想・感情を表現しているものであれば、著作物性が認められる。「データには著作権による保護が及ばない」などと言われることがあるが、著作権により保護されるデータもあり、データとして扱われているからといって一概に著作権による保護が及ばないとは言えない。
学習用データ(データの集合)の著作権保護
事実を示したデータは著作物とは認められないが、そのようなデータの集合がデータベースの著作物として保護される場合がある。データベースの著作物として保護されるには、「情報の選択又は体系的な構成によつて創作性を有するもの」(著12条の2第1項)である必要がある。例えば、リレーショナルデータベースについて著作権侵害を認めた裁判例では、リレーショナルデータベースの創作性を判断するにあたっては、「テーブルの内容(種類及び数)、各テーブルに存在するフィールド項目の内容(種類及び数)、どのテーブルとどのテーブルをどのようなフィールド項目を用いてリレーション関係を持たせるかなどの複数のテーブル間の関連付け(リレーション)の態様等によって体系的構成が構築されていることを考慮する必要があるものと解される。」「正規化がもたらす意義や正規化の程度についても考慮する必要があるものと解される。」と判示されている[3]。
機械学習に用いる学習用データの場合、大量のデータを網羅的に収集したデータの集合体である場合が多いと想定されるため、「情報の選択」に創作性があるとは認められない可能性が高く、また、どんなに大量のデータの蓄積であっても、蓄積しただけでは「体系的な構成」に創作性があるとも考えにくいため、学習用データがデータベースの著作物として認められる場合は限定的であると考えられる。
民法の不法行為による保護
著作権で保護されないデータベースのデッドコピーについて、民法709条の不法行為を認めた裁判例がある。当該裁判例では、デッドコピーされたデータベースについて、データベースの著作物とは認められないとしたものの、「人が費用や労力をかけて情報を収集、整理することで、データベースを作成し、そのデータベースを製造販売することで営業活動を行っている場合において、そのデータベースのデータを複製して作成したデータベースを、その者の販売地域と競合する地域において販売する行為は、公正かつ自由な競争原理によって成り立つ取引社会において、著しく不公正な手段を用いて他人の法的保護に値する営業活動上の利益を侵害するものとして、不法行為を構成する場合があるというべきである」と判示して、民法709条の不法行為の成立を認めている[4]。
しかし、その後に最高裁において、「同条各号〔著6条各号を指す。著6条は保護を受ける著作物を規定している。〕所定の著作物に該当しない著作物の利用行為は、同法が規律の対象とする著作物の利用による利益とは異なる法的に保護された利益を侵害するなどの特段の事情がない限り、不法行為を構成するものではないと解するのが相当である」(〔〕内筆者補足)として、著作権法による保護を受けない著作物については、特段の事情がない限り不法行為は構成しないものと判示されている[5]。
最高裁判決以降、著作権法だけでなく、知的財産法全般にわたって、最高裁の判断を広く一般化したような裁判例が出てきているが、最高裁判決は著作物でありながら著作権法での保護を受けられない著作物についての不法行為の成立を判断したものであり、そもそも著作物ではないものについてまで最高裁判決の射程に含めることは妥当ではなく、著作物として保護されないデータベースのデッドコピーについて不法行為が認められる余地は残されていると説く学説もある[6]。最高裁が「著作権法の保護対象とならない創作物の利用行為は」という旨の表現ではなく、「著6条各号所定の著作物に該当しない著作物の利用行為は」という前置きを付していることからすると、学説で主張されるように、著6号各号に該当しないものにまで最高裁判決の射程を広げることは妥当ではないように考えられる。
このように、最高裁の射程を広く適用することに対しては妥当でないとの指摘があり、その指摘は正しいと考えられるものの、裁判例において最高裁の考え方が広く一般化されて用いられていることは事実であり、著作物と認められないデータベースについて、不法行為による救済を期待することは、現在の実務上はハードルが高いと言わざるを得ないだろう。
EUデータベース権(sui generis right)
EUでは、1996年の欧州データベース指令(Directive 96/9/EC)[7]により、著作物にならないデータベースに特別の権利が与えられている。データベースのコンテンツの入手、検証、表示のいずれかに対して投資を行ったことを証明した作成者に対して、データベースのコンテンツの全部又は実質的な部分を抽出・再利用することを排除する権利が与えられ(指令7条)、データベースの完成の翌年から15年間の保護が与えられる(指令10条)。
データベース権の課題として、次のようなものが先行研究で挙げられている[8]。まず、データの入手に対する投資(既存のデータを基にしたデータの集合)は保護されるが、新たなデータの創出に対する投資は保護されないとされている。したがって、AIの学習用データとして利用されるような機械やセンサーによって収集が行われたデータベースは保護されないと解釈されている。また、抽出・再利用の概念が非常に広く、データベースのごく一部の利用でも侵害になる恐れがあり、情報解析を阻害する恐れが懸念されている。さらに、データを更新し、その更新に量的または質的に新たな実質的投資が行われたとされると、保護期間も更新されるため、保護期間が永続しかねないことが懸念されている。
以上のようにデータベース権には多くの懸念が指摘されているところ、2020年11月に欧州委員会が公表した「EUの復興とレジリエンスをサポートする知的財産行動計画」において、機械生成されたデータやIoTの展開に伴うデータについて、共有と取引を容易にするためにデータベース指令を見直すとの記載がなされている[9]。
AIプログラム・学習済みモデルの著作権法制
AIプログラムの著作権保護
著作権法10条は著作物を例示しており、そこに「プログラムの著作物」も挙げられている(著10条1項9号)。AIプログラムも、思想・感情の創作的表現であると認められれば、著作物として保護される。
ただし、著作物として保護されたとしても、そのプログラムで表現されたアルゴリズム自体が保護されるわけではない。そのため、同じアルゴリズムを体現するプログラムであっても(同じ動作をするプログラムであっても)、その表現が異なれば著作権侵害にはならない。これは、著作権法はあくまで思想・感情の「表現」を保護するものであり、「アイデア」そのものは保護しないという考え方によるものである(アイデア・表現二分論)。条文上も、プログラムの著作物に対する保護は、その著作物を作成するために用いるプログラム言語、規約(プロトコル)、解法(アルゴリズム)には及ばないと規定されている(著10条3項)。
学習済みモデルの著作権保護
経済産業省が公表している「AI・データの利用に関する契約ガイドライン」では、「学習済みモデル」を、「『学習済みパラメータ』が組み込まれた『推論プログラム』をいう」と定義している。「推論プログラム」とは、「組み込まれた学習済みパラメータを適用することで、入力に対して一定の結果を出力することを可能にするプログラムをいう」とされ、「学習済みパラメータ」とは、「学習用データセットを用いた学習の結果、得られたパラメータ(係数)をいう」とされている。本稿でも経済産業省のガイドラインの定義を用いる。
推論プログラムの著作権保護については、前述したAIプログラムの著作権保護の場合と変わるところはない。また、学習済みパラメータについても、学習の結果得られたものではあっても、単なるパラメータであり、かつ、自動で学習され出力されるものであれば人間の関与もないことから、創作性は認められないと考えられ、前述したデータの場合と同様に著作権による保護は難しい。また、学習済みパラメータはデータの集合とも言えるが、自動で学習されるものであるため、情報の選択や体系的な構成に創作性があるとも言い難く、データベースの著作物としての保護も難しいと考えられる。
以上から、学習済みモデルについては、推論プログラムの部分には著作権が認められる場合が多いと考えられる一方、学習済みパラメータの部分には著作権が認められない場合が多いと考えられる。
機械学習の著作権法制
機械学習を行う際の学習データには、画像データや文章データなど、著作権で保護されるデータも含まれ得る。著作権で保護されたデータを機械学習で扱う場合に関連して、2018年の著作権法改正において、「デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定の整備」を目的とした規定が導入された。以下、機械学習に関連する代表的な規定として、著30条の4を概説する。また、諸外国における情報解析に関する著作権の権利制限規定として、米国のフェア・ユース規定と、EUのデジタル単一市場著作権指令(以下「DSM著作権指令」)3条及び4条を概説し、日本の著30条の4との簡単な比較を行う。
著30条の4(思想・感情の非享受利用)
著30条の4は、思想・感情の非享受利用を許容する規定である。著作物は通常、物語を読む、絵画を鑑賞する、音楽を聴く、といった行為を通じた表現の享受に対価が支払われており、著作物に表現された思想又は感情に対して経済的価値が生まれていると言える。そのような思想・感情の享受を目的としない著作物の利用は、著作権者が想定していたであろう思想・感情の表現の持つ経済的価値からの対価回収機会を損なうものではないことを理由に、著作権を制限することを正当化するのが著30条の4である[10]。
著30条の4は、どのような場合が適用対象になるかを各号で列挙しており、2号に情報解析の用に供する場合が挙げられている。2号は、「情報解析」を「多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うこと」と定義している。機械学習は2号の情報解析に該当すると考えられることから、機械学習の過程で著作物を利用する行為は、その機械学習に必要な限度において、著作権侵害には問われないことになる。なお、各号に示された利用態様以外の利用であっても、「著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合」であれば、必要と認められる限度において広く権利制限が認められるため、上記「情報解析」の定義に当てはまらない機械学習の手法が存在しても、著30条の4に該当する可能性は残されている。
ただし、著30条の4には「ただし書」があり、著作権者の利益を不当に害することとなる場合は権利制限の対象にはならないことが規定されている。このただし書については、参議院文教科学委員会において、「柔軟な権利制限規定の導入に当たっては、現行法において権利制限の対象として想定されていた行為については引き続き権利制限の対象とする立法趣旨を積極的に広報・周知すること」との附帯決議[11]が付されていることから、ただし書に該当するのは、著30条の4のベースとなった著旧47条の7(電子計算機による統計的解析に関する権利制限規定)において権利制限に該当しない利用とされていた解析用データベースの利用にとどまると論じる説[12]もある一方、附帯決議に示された立法趣旨のみからそのような解釈を行うことは相当無理なものであり、将来における著作物の潜在的販路を阻害する可能性のある利用も、解釈次第ではただし書の対象となる可能性があり、著旧47条の7よりも権利制限の範囲が狭くなる可能性が出てくると論じる説[13]もある。
私見としては、著30条の4は、著作物の思想・感情の非享受目的の利用は、通常は対価回収機会を損なわないものであるということを権利制限が正当化される根拠としていることから、既に市場に存在する対価回収機会を損なうような場合は、解析用データベースの利用に限らずただし書の対象としても立法趣旨に反するものではないと考えられる。しかし、現存しない将来的な対価回収機会の可能性を想定し、ただし書に該当すると判断されるのならば、およそどのような形態の利用であっても対価回収機会の可能性を論じることはできようから、ただし書に該当する可能性があることになり、著30条の4のような柔軟な権利制限規定を設けた趣旨が没却されかねない。したがって、あくまで現存する対価回収機会を損なうものであるか否かをただし書の該当判断基準とすべきであると考える。なお、現存する対価回収機会の有無については、対象となる著作物の市場において業界慣行として定着しているといった事情があることを判断基準とすべきであろう。
米国:フェア・ユース
米国のフェア・ユース(米国著作権法107条[14])は、情報解析での利用にとどまらない包括的な権利制限規定であり、①使用の目的及び性質、②著作物の性質、③使用された量及び実質性、④著作物の潜在的市場への影響という4つの要素を総合的に考慮して、フェア・ユースであるか否かが判断され、フェア・ユースであれば権利が制限されるというものである。フェア・ユースの判断においては、第1要素と第4要素の影響が大きいとされている。
4つの要素は抽象的であるため、最新の情報技術にも柔軟に対応できるという利点がある一方で、曖昧な判断基準であるが故にどのような利用であればフェア・ユースに該当するのか分かりづらいという批判もある。また、以前はフェア・ユースが認められると考えられていた利用が、市場の変化によってフェア・ユースが認められなくなる可能性もある。例えば、1973年のWilliams & Wilkins判決[15]では、医療系図書館の複写サービスについてフェア・ユースが認められたが、1995年のTexaco判決[16]では、Texaco社の研究者が社内で回覧されていた雑誌論文を複写していた行為に対してフェア・ユースが認められなかった。Williams & Wilkins判決とTexaco判決とで判断が異なる要因としては、複写が研究機関や図書館等によるものであるか、営利企業によるものであるかという点の違いがあるものの、Williams & Wilkins判決後に、Copyright Clearance Center(CCC)という文献複写を許諾するための著作権の集中管理機構が創設され、複写に対するライセンス市場が成立していたことが大きいと考えられている[17]。
フェア・ユースの判断基準の代表的な理論には、「市場の失敗理論」と「変容的利用の理論」がある[18]。「市場の失敗理論」では、フェア・ユースは市場の失敗を治癒するものであるとされており、上記のTexaco判決は市場の失敗理論を採用したとされている。「変容的利用の理論」では、利用された著作物の本来の目的から見て、その利用がどの程度変容的かで判断されるものであるとされる。例えば、Google Books判決[19]においては、全文検索提供のための書籍の複製やデータベースの作成、検索での利用とスニペット表示について、変容的利用の理論に基づき、フェア・ユースが肯定されている。
機械学習のような情報解析での著作物の利用については、変容的利用に該当する可能性が高く、フェア・ユースに該当すると考えられるものの、最終的な判断は裁判で争われなければ分からないという状況である。
EU:DSM著作権指令3条・4条
EUは、加盟国間で異なる法律や制度などを整備し、域内のデジタル市場の統合を目指す「デジタル単一市場」(DSM:Digital Single Market)の実現を政策目標として掲げており、2019年6月に発効されたDSM著作権指令[20]もDSMを実現するためのものである。
本指令には指令3条・4条にテキスト・データマイニング(TDM)に関する規定がある。TDMは、「情報を生成するために、デジタル形式でテキストやデータを分析することを目的としたあらゆる自動化された分析技術」と定義されており(指令2条(2))、デジタル形式であることに限定されない日本の著作権法と比べると対象が限定されているものの、機械学習のような情報解析は含まれると考えられる。
指令3条は、学術研究目的でのTDMを規定している。指令3条の対象となるのは、原則として非営利の研究機関(大学や大学図書館、研究所等)及び文化遺産施設(図書館、博物館、公文書館等)に限られる。これらの機関は、後述する指令4条と異なり、権利者による留保の有無を問わず、学術研究目的のためのTDMに著作物等(データベース権により保護されるもの等も含むため、著作物「等」としている。)を利用することができる。また、権利者は著作物等がホストされているネットワークやデータベースのセキュリティ・安全性を確保するための措置を講じることは認められるが、セキュリティ・安全性確保以上の措置は認められないとされており、例えばTDMを妨げるための技術的措置は認められないと考えられる。
指令4条は、指令3条と異なり、特に対象を限定しないTDMを規定している。したがって、営利目的でのTDMも指令4条により認められている。ただし、指令4条によるTDMは、権利者が著作物等のTDMによる使用を明示的に留保している場合には適用されないとされている。したがって、例えば、映画中に「この作品のTDMは認めない」といった旨の表示がされていた場合、その映画のTDMは認められないと考えられる。
なお、DSM著作権指令は、直接加盟国に適用される「規則」(Regulation)ではなく、「指令」(Directive)であることから、加盟国による国内法化が必要になる。加盟国は、2021年6月7日までに指令に応じた国内法を整備し、施行しなければならない(指令29条)。
日本、米国、EUの比較
日本、米国、EUの機械学習に関する著作権の権利制限規定を表にまとめた(表1)。比較してみると、日本の著30条の4は、米国と比べると適用対象は限定されるものの、米国よりも権利制限される場合が明確であるため、権利侵害のリスクを事前に回避するという観点からは、米国に比べて非常に使いやすいものであると考えられる。
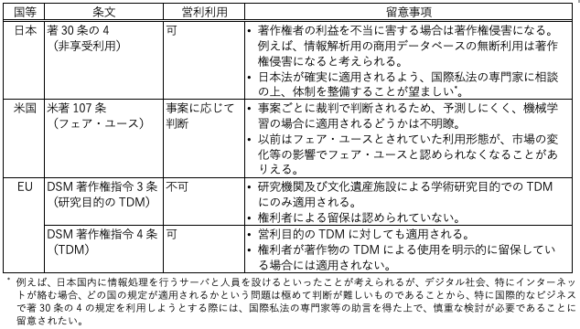
【表1】機械学習に関する著作権の主な権利制限規定比較
(出典:各種公表資料をもとに筆者作成)
また、EUと比較しても、日本の規定は使いやすいものであると考えられる。DSM著作権指令3条は営利目的では利用ができず、指令4条では営利目的での利用ができるものの、権利者による留保が認められている故に、機械学習での著作物の利用が権利者の利益を害さないものであるとしても、権利者が拒否する限り、自由に利用することはできない。一方、日本の規定は、著作権者の利益を不当に害する場合でなければ利用することができ、仮に権利者が「機械学習に使用してはならない」と明示的に留保していたとしても、権利者の利益を不当に害さないものであれば、少なくとも著作権侵害にはあたらないと考えられる。
日本の著30条の4は、機械学習で著作物を利用する側にとって非常に使い勝手の良い制度であり、日本国内での行為であれば外国企業であっても適用を受けることから、日本は「機械学習パラダイス」であると外国で紹介している有識者もいる[21]。少なくとも著作権法においては、機械学習における法的障壁は、日本は諸外国に比べて最も低いと言っても過言ではないだろう。
AI生成物の著作権法制
AI生成物の著作権については、1993年に文化庁の審議会において、コンピュータ生成物の著作権について検討が行われており、当時の見解をまとめた報告書(以下「第9小委報告書」)が公開されている[22]。約30年前の議論であるが、AI生成物の著作権の現在の議論と考え方や結論は変わらない。
以下、AIを道具として使用する場合と、AIが自律的にコンテンツを生成する場合のAI生成物の著作権の考え方について概説する。
AIを道具として使用する場合
第9小委報告書では、当時の技術を踏まえた詳細な検討がなされており、少なくとも当時や近い将来の技術では、人が全く介在しないコンピュータによる創作は難しく、当該創作過程には何らか人が介在するものであるとして、人が道具としてコンピュータを使った場合には、コンピュータによる創作物を著作物として認める余地があるとしている。第9小委報告書は、人がコンピュータを用いて著作物を創作したと認められるためには、①思想・感情をコンピュータを用いて、結果物として表現しようとする創作意図があること、②創作過程において、創作的寄与と認めるに足る行為を行っていること、③生成物が客観的に見て、思想・感情の創作的表現と言える外形を備えていること、以上3つの要件を満たす必要があるとする。
コンピュータ生成物の著作者については、第9小委報告書は、通常の場合、コンピュータ・システムの使用者であるとする。ただし、使用者が単なる操作者であって、何ら創作的寄与が認められない場合には著作者とは認められず、創作的寄与を行ったか否かは個々の事例に応じて判断するしかないとされている。また、コンピュータ・システムのプログラム作成者は、通常の場合、単に道具を作った者にとどまるため、コンピュータ生成物の著作者とは認められないと考えられるが、例えば、使用者とプログラム作成者が特定の生成物を作る意図をもって、プログラム作成者がその生成物を生成するための専用のプログラムを作成した場合には、プログラム作成者も使用者と共同で著作者になり得るとする。
以上の第9小委報告書の考え方は、AIを道具として使用する場合のAI生成物の著作権についても同じように当てはめることができる。
AIが自律的にコンテンツを生成する場合
第9小委報告書は、著作権法の著作物の定義は、その立法趣旨から、思想・感情を「人が」創作的に表現したものであることを当然の前提としているものと一般に解されているとして、コンピュータ生成物でその作成過程に人の創作的寄与が認められない場合は、当時の著作権法上、著作物に該当しないと解されると報告している。この見解については、知的財産戦略本部の検証・評価・企画委員会に設置された次世代知財システム検討委員会が2016年に取りまとめた報告書(以下「次世代知財システム報告書」)[23]も同様の認識を示しており、現行法においても同様に考えられている。
AI生成物が著作物と認められるためには人の創作的関与が必要であるという前提は、世界的にもほぼ共通した見解になっている[24]。例えば、サルが自撮りをした写真について、サルが著作者であるかどうかが争われた米国の裁判例では、これまでの裁判例では著作者は人間であることが言及されていたこと、米国著作権局のガイドラインにおいて、著作者による著作物と認められるためには人間によって創作されていなければならないと記載されていることを挙げ、サルは著作権法上の著作者ではないと判断している[25]。なお、英国著作権法には、コンピュータ生成物の著作者は「創作に必要な手筈を引き受ける者」とする条文があり(英国著作権法(CDPA)[26]9条(3))、「コンピュータ生成」とは、「著作物の人間の著作者が存在しない状況において著作物がコンピュータにより生成されることをいう。」(同法 178条)と定義されており、コンピュータ生成物に著作物性を認めている。ただし、どのような場合に該当するのかについては議論が成熟しておらず、創作過程における一切の人間の関与がない場合にも適用されるのかは明らかではない。仮に全く人間の関与がない場合に著作物性が認められるものであったとしても、条文の文言からすると、AI自身がAI生成物の著作者になるわけではなく、あくまで人間が著作者となると考えられる。したがって、英国法下では、全く人間の関与がない場合の著作者は通常、当該AIのプログラマになるのではないかと考えられる。
次世代知財システム報告書は、あらゆるAI生成物を保護対象とすることは保護が過剰になるとするものの、AI生成物に対するフリーライド抑制等のため、一定の「価値の高い」AI生成物に限って、著作権等とは異なる新たな保護の仕組みを講じることが考えられる、との見解を示している[27]。この見解に対して、奥邨は、新たな保護の仕組みを導入すると、AIによるコンテンツであるにもかかわらず人間の手によるコンテンツであると僭称する、僭称コンテンツ問題を生むことを懸念し、僭称コンテンツ問題を解決するために、思想・感情の要件を改めてAI生成物も著作権法で保護することを検討している[28]。
ヒトDTCへのデータ・AIの著作権法制の議論の適用に関する若干の検討
ヒトDTCの概要
従来のデジタルツインは、実世界の物理的な対象をサイバー空間に写像し、それに対して分析等を行うものであったのに対して、NTTが実現を目指すDTCは、「多様なデジタルツインを自在に掛け合わせて様々な演算を行うことにより、これまでになく大規模かつ高精度な実世界の再現、さらには実世界の物理的な再現を超えた、ヒトの内面をも含む相互作用をサイバー空間上で実現することを可能とする新たな計算パラダイム」であり、「デジタルツイン演算により、実世界とは異なる条件についても、実世界の『再現』という範囲を超えて、サイバー空間においてシミュレーションし、実空間で活用していくこと」を目指すものであるとされている[29]。
DTCの大きな特徴の一つとして、ヒトの内面までの再現に挑戦することが挙げられており、「ヒトの外面だけでなく内面、例えば意識や思考などまで表現することによって、ヒトの行動やコミュニケーションなどの社会的側面についても高度な相互作用を行うことが可能となる」「ヒトそれぞれの個性まで表現することで、平均として統計的に丸められた無個性な個体間の相互作用ではなく、個々人の特徴を踏まえた多様性に基づく相互作用が可能となる」とされている[30]。そして、ヒトの行動傾向や性格、価値観をモデル化した人格・思考モデルや、知覚、知識、言語能力、身体能力などをモデル化した能力モデルといったヒトの個性・特徴を再現するモデルがデジタルツインの振る舞いを規定し、サイバー空間においてデジタルツインが他者からの働きかけに対してあたかも本人のように自律的に反応するとともに、本人のように他者に対して働きかけを行うこともできるようにするとされている。ヒトのデジタルツインを発展させ、利用可能とするシステム全体をNTTは「ヒトDTC」と定義している(図2)[31]。
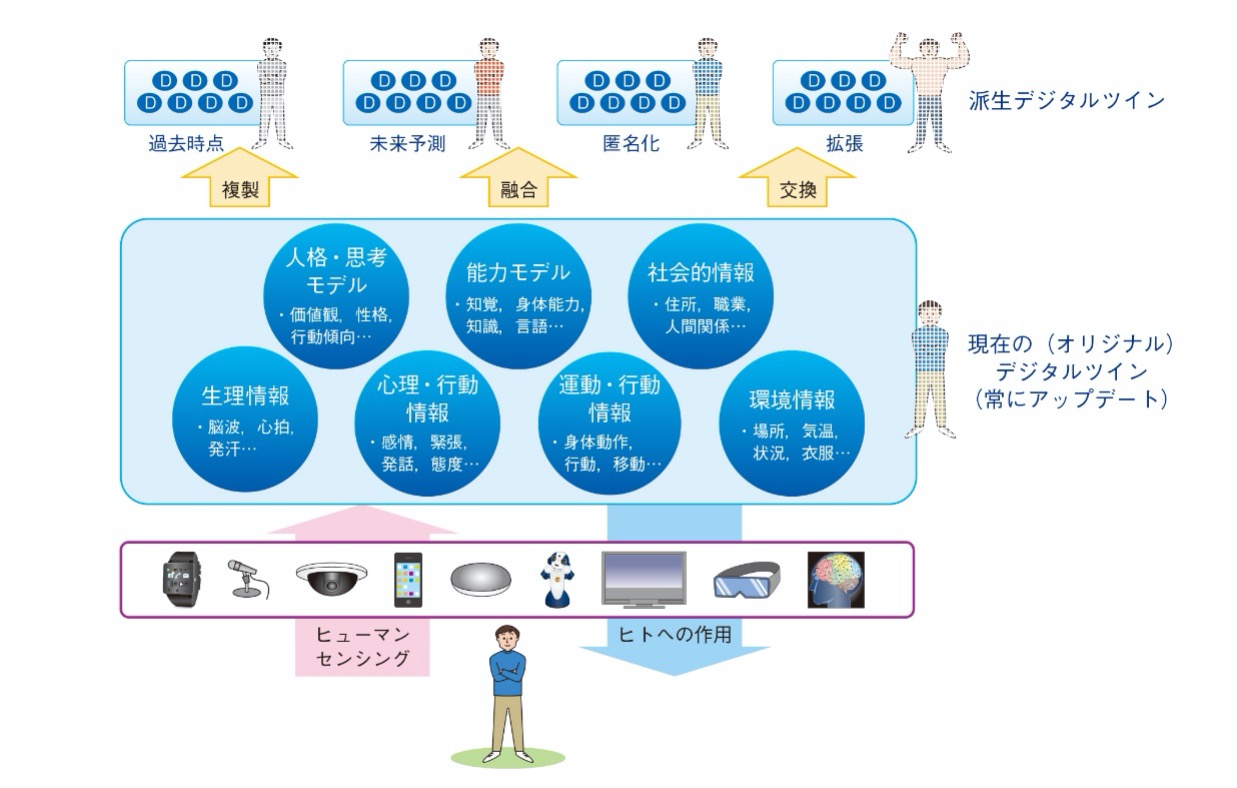
【図2】DTCにおけるヒトのデジタルツイン
(出典:戸嶋巌樹ほか「ヒトDTCの挑戦と今後の展望」NTT技術ジャーナル32巻7号13頁・図2(2020)(https://journal.ntt.co.jp/ article/5786))
以下、ヒトDTCの著作権法上のいくつかの論点について、簡単に検討する。なお、本稿では、システム全体を指す場合は「ヒトDTC」、ヒトDTCで実現される個々の人間のデジタルツイン(DT)は「ヒトDT」と呼ぶことにする。
ヒトDTC実現のためのデータ解析における著作物の利用
ヒトDTCの実現にあたっては、実世界の著作物を含む多種多様なデータを収集し、それらの分析を行うことが必要になると考えられるところ、DTCを生成する過程における著作物の利用は、著作物に表現された思想・感情を享受するための利用ではなく、情報解析に用いるための利用であると考えられることから、前述した著30条の4の適用を受け、著作権侵害とはならないと考えられる。
なお、ヒトDTは元となった人間を再現するものであるから、例えば画家のヒトDTを実現する際に、過去の絵画等のデータも収集されることが想定され、データとして取り込んだ絵画と似た絵画をヒトDTが生成することも考えられる。その場合は、ヒトDTCでの処理自体は問題ないであろうが、その生成物については、依拠性があるかという点が議論になるものの、取り込んだ著作物の権利侵害が成立し得る。もっとも、ヒトDTの生成の際には、元となった人間の同意を得た上でデータが提供・解析されるものと推測されることから、データ提供の契約時にそういった問題には対応可能であるとも考えられる。
ヒトDTによる生成物の著作物性
ヒトDTCにおける従来のAIと異なる点として、人間の内面までも再現することを掲げる点が挙げられる。従来の著作権法の議論においては、「AIには思想・感情がない。したがって、AI生成物は思想・感情を表現したものではない」という前提から、AI生成物には著作物性は認められないという議論がなされていた。しかし、ヒトDTCで再現されたヒトDTが人間の思想・感情を持つものである場合、ヒトDTによる生成物は「人間の思想・感情を表現したもの」であると言える余地が生まれるのではないか。「思想・感情」は、著作権法においては「人の考えや気持ち」程度の意味と捉えられ、思想・感情から漏れるものを著作権保護から排除するという視点からの検討が主になされており[32]、「思想・感情」自体が何を意味するのかという議論は積極的にはなされていない。しかし、ヒトDTが人間の思想・感情を再現できるのであれば、今後は著作権法における「思想・感情」自体が何を意味するのか、思想・感情は著作者を自然人に限定するための要件なのか、仮にそうだとして、それが今後の社会においても適切な制度の在り方なのか、といった議論が必要になるだろう。
また、前述した奥邨による提案[33]のような、思想・感情の要件を改め、思想・感情の有無を問わず、ヒトDT生成物の著作物性を肯定する、という考え方もあり得る。この学説の考え方を採ることで、思想・感情をヒトDTは持つのか、といった極めて証明が難しいことが予想される検討を行うことなく、ヒトDT生成物の保護が実現できるものと考えられる。ただし、奥邨による提案はあくまで人間の内面を再現することを想定しない、従来のAIを前提とした議論であると考えられ、人間の内面を再現したヒトDTを想定する場合に、同様の枠組みに当てはめることが適切かは、従来のAIとヒトDTCとの技術的な内容の比較も含めて差異を明らかにした上での検討が必要だろう。
ヒトDT生成物の著作者あるいは著作権の原始的帰属者
ヒトDTを道具として用いる場合
ヒトDTに具体的な指示を与えて創作をさせるなど、ヒトDTを単なる道具として人間が用いた場合には、創作的表現に対する寄与度に応じて、道具として用いた人間が著作者になり得ることは、従来のAI生成物の著作権に関する議論と同様と考えられる。
ただし、どの程度の創作的寄与があれば著作者として認められるかという点に関しては、ヒトDTの行動や表現が、元となった人間のデータが反映された結果生じているものであることからすると、ヒトDTを道具として用いる者が元となった人間である場合には、従来のAI生成物に関する創作性が認められるであろう寄与度よりも低いレベル、例えば、それほど具体的ではないが表現に関する指示を与えた場合や、ヒトDTの生成物を最後にチェックした程度であっても、元となった人間に著作者としての地位が認められることがあり得るかもしれない。
ヒトDTが自律的に創作をする場合
ヒトDTが自律的に創作し、ヒトDTによる創作過程には元となっている人間含め、人間が関与していない場合に、仮にヒトDTによる生成物に著作権による保護を認めるとするならば、誰が著作者あるいは著作権の原始的帰属者となるのか、あるいは、なるべきか。ヒトDT生成物が著作権で保護されるには、例えば前述したように、①ヒトDTが「思想・感情」を持つと認めた上で、人間以外も思想・感情を持つものであれば著作者と認められると解釈し、ヒトDT生成物を保護する、②思想・感情の要件を改めて、思想・感情の有無を問わず、AI生成物を含めてヒトDT生成物を保護する、という2通りの考え方があり得る。
まず、①ヒトDTが「思想・感情」を持つと認め、人間以外も思想・感情を持つものであれば著作者と認められると解釈する場合については、著作権法の「思想・感情」に関しては議論が成熟しておらず、思想・感情が認められれば自然人ではないヒトDTが著作者となれるかは不明である。また、職務著作(著15条)では、法人が著作者になれるとされているものの、条文上、法人の発意に基づいて自然人が創作行為をしていることが前提となっていると考えられることから、仮にヒトDTを法人とする規定を設けたとしても[34]、法人(ヒトDT)が創作した場合に著作者と認められるかどうかは、今後議論が必要になるものと考えられる[35]。
次に、②思想・感情の要件を改めて、思想・感情の有無を問わず、AI生成物を含めてヒトDT生成物も保護するという考え方については、著作者あるいは著作権の原始的帰属者に関し、奥邨は、映画の著作物の著作権の帰属に関する著29条1項から着想を得て、AI生成物の製作に発意と責任を有する者を著作権の原始的帰属者とする立法案があり得ると述べている。この場合、AI自身は著作者になれないため著作者はいないことになるが、奥邨はAI生成物では特段問題ないと考えられるとし、著作権の原始的帰属者はいても著作者はいないとする[36]。ヒトDTの場合にも同様の枠組みを当てはめることが可能と考えられるが、ヒトDTが従来のAIと比べて極めて高い自律性を持ち、サイバー空間上で自由に創作を行うとすると、ヒトDT生成物の製作に発意と責任を有する者が誰になるのか、という課題が生じる。実際のヒトDTCを用いたサービスでは、ヒトDTの元となった人間が自身のためにヒトDTを利用する(例えば自分の代わりに創作をさせる)、あるいは、第三者が何らかの利益を得ることを目的にヒトDTCサービスを利用することが多いと予想されることから、人間による一切の関与がない状態で、ヒトDTが完全に自律的に創作を行うことは想定しなくてもよいのかもしれない。一方、自分以外の人間のヒトDTを利用する場合に、先の学説によれば利用者が著作権者となることが想定されるが、当該学説ではあくまで一般のAI、特定の個人を思想レベルまで再現したAIではないものを想定していることに留意が必要である。ヒトDTの場合、ヒトDTの生成には元となった人間のデータが非常に大きな貢献を果たしていると考えられることから、仮にヒトDT生成物の生成に元となった人間が直接関わっていない場合であっても、元となった人間が著作権者の一人として認められる可能性が高いのではないかと考えられる。
ヒトDTの元となった人間との関係
上記①・②いずれの場合であっても、ヒトDTは元となった人間の振る舞いを再現するものであるから、ヒトDT生成物は、元となった人間が創作するであろう表現に近いものとなることが想定される。仮に元となった人間に、自身のヒトDT生成物に関する権利を何ら認めない場合、元となった人間がヒトDT生成物と似た著作物を創作すると、ヒトDT生成物の著作権を侵害することになる恐れが生じる。著作権は相対的独占権であるから、独自創作であるならば本来は問題にはならない。しかし、他人のヒトDTやAIが生成したものならばともかく、ヒトDTの生成には自身の様々なデータが必要であり、そのデータの取得には本人の同意が必要であるとすると、それほど重要なデータを提供しているにもかかわらず、自身のヒトDTが生成したものを含む、自身のヒトDTの動向を全く把握していないという主張は認められづらいのではないか。そうすると、ヒトDTCを利用することで自身の創作活動に支障が生じ得ることから、ヒトDTCの利用を避ける恐れがあり、表現活動を行う者ほど、ヒトDTCを利用しないといったことが生じる可能性がある。
ヒトDTCの利便性を享受し、元となった人間の創作のインセンティブを保つという観点からは、ヒトDT生成物の著作権は、元となった本人に対しては行使できないといった制度設計を行うことや、ヒトDT生成物の著作者あるいは著作権の原始的帰属者には元となった人間も含まれると解釈することが妥当ではないかと考える。
あるいは、ヒトDTCサービスの設計として、ヒトDT作成にあたっては、ヒトDTによる生成物の最終チェック等を含めて、元となった人間によるコントロールを必須とすることが考えられる。そうすることで、ヒトDTの創作過程に必ず元となった人間が介入することになり、権利問題も解決しやすくなる。また、ヒトDTによる生成物の最終的なチェックを元となった人間が行うことで、ヒトDTの自律的な行動が元となった人間に不利益を与えることも防止することができ、ヒトDTCサービスの利用者が安心感を得ることができるのではないか。
おわりに
データ・AIの著作権法制について、日本の著作権法は世界的に見ても著作物の自由な利用を認めており、著作権の存在がAI関連の技術開発の支障になることは多くないと考えられる。少なくとも、著作権法を理由に日本のデータ・AI戦略が世界に後れを取るということはなさそうである。
一方でヒトDTCに関しては、著作権法上の論点をいくつか挙げ、若干の検討を行ったが、詳細な検討にあたっては、元となった人間を思想・感情含めてどれほど再現できるのか、ヒトDTはどの程度自律的に行動できるのかといった点を明らかにした上で(あるいは仮定した上で)、その度合いに応じた検討をすることが望ましいと考える。なぜなら、再現や自律の度合いが低いのであれば、従来のAIと同様の議論が当てはまる部分が多くなるであろうし、逆に再現や自律の度合いが高いのであれば、従来のAIの議論ではほとんど議論がなされていなかったであろう、思想・感情を含めて人間の内面が再現されたヒトDTを想定した検討が必要になると考えられるためである。また、思想・感情を含めて再現されたヒトDTを想定した検討にあたっては、そもそも「思想・感情」とは何なのか、ヒトDTが技術的にどのようにして思想・感情を再現しているのか、といった法学にとどまらない学問分野を横断した検討が求められるだろう。
本稿は、データ・AIに関する著作権法制の従来の議論をごく簡単にまとめ、ヒトDTCとの関係についても若干の検討を行ったものにとどまるが、今後のヒトDTCと著作権法制の議論の一助となれば幸いである。
[1] NTT「IOWN」NTT R&D Website(https://www.rd.ntt/iown/)。
なお、本稿で挙げるWEBサイト情報は、すべて2021年3月11日に最終閲覧した。
[2] NTT「デジタルツインコンピューティングとはなにか」NTT R&D Website(https://www.rd.ntt/iown/ 0003.html)。
[3] 知財高判平成28年1月19日・平成26(ネ)10038。
[4] 東京地中間判平成13年5月25日・平成8(ワ)10047等。
[5] 最一小判平成23年12月8日民集65巻9号3275頁。
[6] 上野達弘「著作権法に関する最高裁判決の射程:最高裁判決のミスリード?」コピライト686号26-28頁(2018)。
[7] Directive 96/9/EC (https://eur-lex.europa.eu/ legal-content/EN/TXT/?uri=celex:31996L0009). 日本語訳として、山本隆司訳「外国著作権法:EU編 データベース指令」著作権情報センター(2021)(https://www.cric.or.jp/db/world/EU/EU_Y_index_04.html)。
[8] 山根崇邦「ビッグデータの保護をめぐる法政策上の課題:欧米の議論を手がかりとして」パテント73巻8号94-113頁(2020)。
[9] European Commission “An intellectual property action plan to support the EU’s recovery and resilience” (2020)(https://eur-lex.europa.eu/ legal-content/EN/ALL/?uri=CELEX:52020DC0760).
[10] 文化庁「著作権法の一部を改正する法律(平成30年改正)について(解説)」(https://www.bunka.go.jp/ seisaku/chosakuken/hokaisei/h30_hokaisei/pdf/ r1406693_11.pdf)。
[11] 参議院文教科学委員会「著作権法の一部を改正する法律案に対する附帯決議」(2018-05-17)(https://www.sangiin.go.jp/japanese/gianjoho/ketsugi/196/f068_051701.pdf)。
[12] 上野達弘「平成30年著作権法改正について」高林龍ほか編『年報知的財産法2018-2019』3-5頁(日本評論社、2018)。ただし、著旧47条の7が定める利用行為は「記録媒体への記録又は翻案」であることから、これ以外の譲渡や公衆送信といった利用行為については、解析用データベースの利用以外の場合も著30条の4ただし書に当たり得るとする(5頁注8)。
[13] 愛知靖之「AI生成物・機械学習と著作権法」パテント73巻8号141-143頁(2020)。
[14] 日本語訳として、山本隆司訳「外国著作権法:アメリカ編」著作権情報センター(2018)(https://www.cric.or.jp/db/world/america.html)。
[15] Williams & Wilkins Co. v. United States, 487 F.2d 1345 (Ct. Cl. 1973).
[16] American Geophysical Union v. Texaco, 60 F.3d 913 (2d Cir. 1995).
[17] Williams & Wilkins判決とTexaco判決の詳細や米国での議論の分析については、村井麻衣子「フェア・ユースにおける市場の失敗理論と変容的利用の理論 (2) : 日本著作権法の制限規定に対する示唆」知的財産法政策学研究46号95頁以下(2015)を参照。
[18] フェア・ユースの判断基準の代表的な2つの理論についての詳細は、村井麻衣子「フェア・ユースにおける市場の失敗理論と変容的利用の理論 (1) : 日本著作権法の制限規定に対する示唆」知的財産法政策学研究45号105頁以下(2014)を参照。
[19] Authors Guild, Inc. v. Google, Inc., 804 F.3d 202(2d Cir. 2015).
[20] Directive (EU) 2019/790(https://eur-lex.europa. eu/eli/dir/2019/790/oj).日本語訳として、井奈波朋子訳「外国著作権法:EU編 デジタル単一市場指令」著作権情報センター(2021)(https://www.cric.or.jp/db/world/EU/EU_I_index_02.html)。
[21] 上野達弘「著作権法改正が拓く日本の“機械学習パラダイス”」ビジネス法務19巻2号1頁(2018)。
[22] 文化庁「著作権審議会第9小委員会(コンピュータ創作物関係)報告書」(1993)(https://www.cric.or.jp/ db/report/h5_11_2/h5_11_2_main.html)。
[23] 知的財産戦略本部 検証・評価・企画委員会 次世代知財システム検討委員会「次世代知財システム検討委員会 報告書」22頁(2016)(https://www.kantei.go. jp/jp/singi/titeki2/tyousakai/kensho_hyoka_kikaku/2016/jisedai_tizai/hokokusho.pdf)。
[24] 外国での議論状況は、羽賀由利子「AI生成物の著作権法上の取り扱い : 外国の議論状況と若干の国際私法的検討」コピライト60巻716号84頁以下(2020)を参照。
[25] Naruto v. Slater, Case No. 15-cv-04324-WHO (N.D. Cal. Jan. 28, 2016).
[26] 日本語訳として、大山幸房=今村哲也訳「外国著作権法:英国編」著作権情報センター(2016)(https://www.cric.or.jp/db/world/england.html)。
[27] 次世代知財システム検討委員会・前掲注23・26-27頁。
[28] 奥邨弘司「人工知能が生み出したコンテンツと著作権 : 著作物性を中心に」パテント70巻2号14-18頁(2017)。
[29] NTTデジタルツインコンピューティング研究センタ「DIGITAL TWIN COMPUTING:WHITE PAPER / VERSION 2.0.0」6頁(2019)(https://www.rd.ntt/ dtc/DTC_Whitepaper_jp_2_0_0.pdf)。
[30] NTTデジタルツインコンピューティング研究センタ・前掲注29・6頁。
[31] ヒトDTCの詳細については、戸嶋巌樹ほか「ヒトDTCの挑戦と今後の展望」NTT技術ジャーナル32巻7号12頁以下(2020)(https://journal.ntt.co.jp/ article/5786)参照。
[32] 中山信弘『著作権法』50頁(有斐閣、第3版、2020)。
[33] 奥邨・前掲注28。
[34] 民法33条1項(「法人は、この法律その他の法律の規定によらなければ、成立しない。」)により、ヒトDTを法人と認めるためには、法律の規定が必要になる。
[35] なお、AIに法人格を認めるか否かについては、一般に否定的な見解が示されている(例えば、The Expert Group on Liability and New Technologies – New Technologies Formation “Liability for Artificial Intelligence and other emerging technologies” Publications Office of the European Union (2019))。ただ、現在の議論のベースとなっているAIとは異なる、人間の内面を再現するというヒトDTCの特徴を踏まえた再検討の余地までは否定されないように思われる。
[36] 奥邨・前掲注28・16-17頁。保護すべき人格的利益が存在しないことから、著作者人格権は不要であると説く。
※この記事は会員サービス「InfoCom T&S」より一部無料で公開しているものです。
調査研究、委託調査等に関するご相談やICRのサービスに関するご質問などお気軽にお問い合わせください。
ICTに関わる調査研究のご依頼はこちらこの記事をシェアする
関連キーワード
鈴木 康平(退職)の記事



関連記事




InfoCom T&S World Trend Report 年月別レポート一覧

ランキング
- 最新
- 週間
- 月間
- 総合
各種サービスへの問い合わせ



情報通信サービスの専門誌の無料サンプル、お見積り

グローバルICT市場の総合データ集の紹介資料ダウンロード